Data Analyse:
Dispensé par Monsieur Mbiguidi en section DATASCIENCE, école Epsi, Nantes:
Exercice/Contrôle sur Dataset Libre.
Régression linéaire multiple: analyse du dataset Boston Housing
Nous allons utiliser le dataset Boston Housing, qui contient des informations sur des maisons à Boston. Ces données faisaient initialement partie du Machine Learning Repository de l’UCI, mais ont été retirées. Elles étaient également accessibles via la bibliothèque scikit-learn, mais cette méthode deviendra obsolète. Nous allons donc les récupérer à partir de ce lien : http://lib.stat.cmu.edu/datasets/boston.
Le dataset contient 506 échantillons et 13 variables. Nous allons réaliser deux analyses différentes pour cet exercice.
Une première analyse liée au prix des habitations, et une deuxième liée à la criminalité.
Nous essaierons, dans cet exercice, de créer et d’explorer deux modèles différents en faisant des variations de tests.
Chargement des bibliothèques
Tout d’abord, nous chargeons les différentes bibliothèques. Pour ce faire, nous allons coder en utilisant le langage R.
if (!require("dplyr")) install.packages("dplyr")
if (!require("corrplot")) install.packages("corrplot")
if (!require("ggplot2")) install.packages("ggplot2")
library(dplyr)
library(corrplot)
library(ggplot2)
Importation du data set:
Le dataset est actuellement accessible via cette adresse :
http://lib.stat.cmu.edu/datasets/boston
Comme je souhaite l’avoir en local dans mon environnement de travail, j’exécute un code Python que j’ai déjà en ressource, qui me permet de récupérer l’ensemble de la base de données et de l’enregistrer en local dans mon dossier de travail lié aux données, le tout au format CSV
-
Ce code ressemble à ceci: (Cliquer sur la fléche pour dérouler le menu)
import pandas as pd import requests url = "<http://lib.stat.cmu.edu/datasets/boston>" response = requests.get(url) data = response.text.splitlines() data_columns = data[8:18] data_values = data[22:] columns = [] for col in data_columns: columns.extend(col.split()) rows = [] for i in range(0, len(data_values), 2): row1 = data_values[i].split() row2 = data_values[i + 1].split() rows.append(row1 + row2) df = pd.DataFrame(rows, columns=columns) output_file = "boston_housing.csv" df.to_csv(output_file, index=False) print(f"File saved as {output_file}")
Importation et visualisation du dataset dans R
Dans un premier temps, nous importons le dataset dans R, puis à l’aide de la commande head, nous effectuons une première visualisation afin de prévisualiser ce dataset et de se faire une idée de ce qu’il contient.
boston <- read.csv("~/OFwiki/Other_frequencies_Wiki/Code/R/Dev_R/boston_housing.csv", header = TRUE)
head(boston)
On observe une liste de colonnes et voici la méta liée à chacune de ces colonnes:
- CRIM : Taux de criminalité par habitant par ville.
- ZN : Proportion de zones de terrains résidentiels pour des lots de plus de 25 000 pieds carrés.
- INDUS : Proportion d’acres d’entreprises non commerciales par ville.
- CHAS : Variable Dummy Charles River (= 1 si la parcelle borde la rivière ; 0 sinon).
- NOX : Concentration d’oxyde nitrique (parties par 10 millions).
- RM : Nombre moyen de pièces par logement.
- AGE : Proportion de logements occupés par leur propriétaire construits avant 1940.
- DIS : Distances pondérées par rapport à cinq centres d’emploi de Boston.
- RAD : Indice d’accessibilité aux autoroutes radiales.
- TAX : Taux d’imposition foncière sur la pleine valeur par 10 000 $.
- PTRATIO : Ratio élèves/professeurs par ville.
- B : 1000(Bk – 0.63)², où Bk est la proportion de personnes d’origine afro-américaine par ville.
- LSTAT : Pourcentage de la population de statut inférieur.
- MEDV : Valeur médiane (ou prix) des maisons occupées par leur propriétaire, en milliers de dollars.
Voici la visualisation du set de donnée:
![[image.png]]
Analyse du taux de criminalité:
Je suis particulièrement sensible à ce qui influence les environnements sociaux. La criminalité est souvent considérée comme un indicateur des minima sociaux. J’aimerais donc explorer cette direction pour comprendre les éléments de l’environnement social et géographique ayant un impact sur le taux de criminalité.
Tout d’abord, nous allons créer une matrice de corrélations:
Mise en place et étude de la matrice de corrélations
boston_corel <- boston %>% select_if(is.numeric)
cor_matrix <- cor(boston_corel)
corrplot(cor_matrix, method = "circle", type = "upper")
![[image 1.png]]
-
En bleu : il s’agit des points ayant une corrélation à la hausse.
Si on tire vers le haut une variable (x), celle-ci entraînera à la hausse CRIM (y).
On peut observer que plusieurs variables ont un impact à la hausse. On notera que les deux plus fortes sont la variable RAD et la variable TAX.
Pour rappel :
- TAX : Taux d’imposition foncière sur la pleine valeur par 10 000 $.
- RAD : Indice d’accessibilité aux autoroutes radiales.
En d’autres termes :
Les lieux ayant un fort taux de taxe d’habitation et les lieux situés près des autoroutes ont une forte susceptibilité d’être victimes d’un fort taux de criminalité.
Bien qu’il ne s’agisse pour le moment que de suppositions, on peut essayer d’en extrapoler une théorie : les axes autoroutiers sont certainement le moyen privilégié par les criminels pour accéder aux zones où les crimes ont lieu.
D’autre part, les zones les plus susceptibles d’être assujetties à la criminalité sont celles avec un fort taux de taxation. On peut facilement imaginer qu’il s’agisse des lieux ayant un portefeuille moyen plus élevé que dans d’autres zones et, de facto, un confort matériel plus important, ce qui les rend donc plus attrayants pour la criminalité.
-
En rouge : Dans l’autre sens, on remarque que les éléments qui tirent à la baisse le taux de criminalité ont un impact moins important.
Recontextualisation : notre dataset est représentatif des années 1980, une époque où les biais sociétaux étaient plus marqués qu’aujourd’hui, notamment la ségrégation raciale.
Il y a trois éléments qui indiquent, à la baisse, un impact sur la criminalité :
- B : 1000(Bk – 0.63)², où Bk est la proportion de personnes d’origine afro-américaine par ville.
- MEDV : Valeur médiane (ou prix) des maisons occupées par leur propriétaire, en milliers de dollars.
- DIS : Distances pondérées par rapport à cinq centres d’emploi de Boston.
Tout d’abord, le premier point :
On observe que les quartiers afro-américains sont moins sujets à la criminalité.
On pourrait faire un raccourci hâtif et dangereux en adoptant une vision “raciale” pour expliquer le faible taux de criminalité au cœur des quartiers afro-américains. Cependant, un esprit critique nous amènera à chercher la cause sous un autre angle, en corrélation avec le taux de criminalité. Nous pourrions explorer des pistes liées à la répartition des richesses, à la qualité de l’emploi et aux conditions de vie. Ces corrélations sont déjà envisageables grâce à notre matrice. En effet, on peut également observer que les populations afro-américaines sont corrélées avec :
- INDUS : Proportion d’acres d’entreprises non commerciales par ville.
- NOX : Concentration d’oxyde nitrique (parties par 10 millions).
- RAD : Indice d’accessibilité aux autoroutes radiales.
- TAX : Taux d’imposition foncière sur la pleine valeur par 10 000 $.
Une simple connaissance de l’histoire peut nous rappeler que ces populations étaient souvent assignées à des travaux pénibles, peu rémunérés, et concentrées dans des zones où les conditions de vie n’étaient pas favorables (pollution, par exemple).
En d’autres termes, notre matrice mettant en avant ces corrélations, il serait utile de conserver les 4 variables corrélées à cette dimension tout en choisissant d’exclure la variable B de notre étude. En effet, il semble que B soit davantage une résultante qu’une variable de causalité.
Une autre variable qui me semble intéressante à étudier est celle liée au contexte culturel. En effet, l’indice PTRATIO, qui a priori n’est pas l’indice le plus évident en termes d’impact, pourrait nous donner des informations plus précises si nous décidons de le retravailler plus en profondeur, notamment à l’aide de la méthode dummy (nous reviendrons sur cette méthode un peu plus tard).
Enfin, je décide également d’exclure complètement la variable CHAS, étant donné que ses corrélations sont très faibles.
Pour résumer: Je vais exclure de mes observations les variable B, CHAS et je reviendrais sur la variable PTRATIO un peu plus tard dans cette exploration.
Visualisation de la distribution
Dans un second temps, nous allons faire un histogramme de la variable Y (CRIM)
ggplot(boston, aes(x = CRIM)) +
geom_histogram(binwidth = 1, fill = "blue", alpha = 0.7) +
labs(title = "Distribution du taux de criminalité (CRIM)", x = "CRIM", y = "Fréquence")
ce qui nous donne ceci:
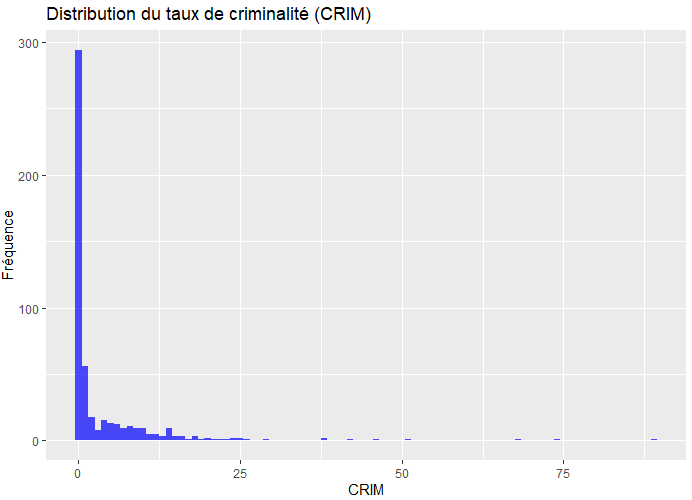
En observant la distribution de votre graphique, voici quelques points que l’on peut déduire sur la variable y CRIM (taux de criminalité) :
- Distribution asymétrique avec un pic élevé :
- La majorité des villes ont un taux de criminalité très bas, concentré autour de 0.
- Cela indique que les zones à faible criminalité sont dominantes dans l’échantillon.
- Queue longue à droite (positivement asymétrique) :
- Il existe quelques villes avec des taux de criminalité très élevés (outliers ou valeurs extrêmes).
- Cela pourrait refléter des quartiers très spécifiques avec des problèmes de criminalité nettement plus importants.
- Analyse des valeurs extrêmes :
- Ces valeurs extrêmes pourraient être influencées par des facteurs spécifiques comme la densité urbaine, le revenu moyen, ou d’autres caractéristiques particulières de ces quartiers.
Le taux de criminalité est très inégalement réparti dans l’échantillon, avec une concentration autour de faibles valeurs et quelques cas de criminalité élevée qui méritent une analyse plus approfondie.
Graphiques de dispersion:
En explorant les graphiques de dispersions, nous allons essayer d’obtenir d’autres informations nous permettant d’affiner notre approche de la problématique initiale:
Choix des features
- DIS (Distance aux centres d’emploi) : Influence possible de l’éloignement des centres économiques sur la criminalité.
- LSTAT (% de population faible) : Hypothèse qu’un statut socio-économique faible pourrait être corrélé avec une criminalité élevée.
- AGE (Proportion de logements anciens) : Les zones avec des logements anciens pourraient être associées à des environnements spécifiques influençant la criminalité.
- NOX (Concentration d’oxydes nitriques) : Les zones industrielles, souvent associées à une pollution élevée, pourraient aussi avoir un lien avec le taux de criminalité.
- TAX (Taux d’imposition) : Les zones avec des impôts élevés pourraient être associées à des revenus plus élevés et une augmentation de criminalité.
Relation entre CRIM et DIS :
ggplot(boston, aes(x = DIS, y = CRIM)) +
geom_point(alpha = 0.4) +
geom_smooth(method = "lm", color = "red")
Une plus grande distance (DIS) pourrait indiquer des zones résidentielles éloignées avec moins de criminalité, ou au contraire un isolement favorisant certains comportements criminels.
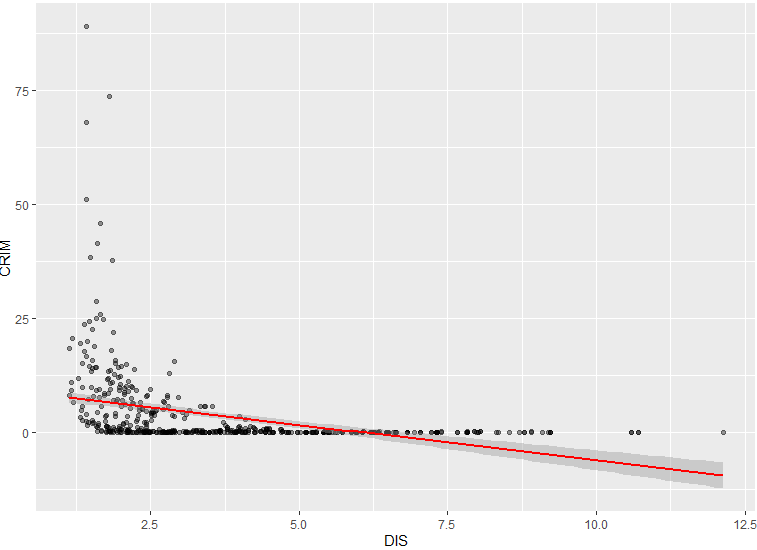
- Bande rouge (ligne de régression)
- Elle représente la relation linéaire estimée entre la variable indépendante DIS (distance aux centres d’emploi) et la variable dépendante CRIM (taux de criminalité). C’est la meilleure droite ajustée qui minimise la somme des carrés des résidus (écarts entre les points réels et la droite).
- La direction indique une relation négative entre DIS et CRIM. Cela signifie que plus la distance aux centres d’emploi est grande, plus le taux de criminalité tend à diminuer.
- Bande grise (intervalle de confiance) :
- Cette bande représente un intervalle de confiance à 95 % pour la ligne de régression.
- En d’autres termes, cette bande montre la plage dans laquelle la vraie relation entre DIS et CRIM a 95 % de chances de se situer.
- Cette bande est étroite, cela signifie que la relation est estimée avec une précision relativement élevée. (Une bande large indique plus d’incertitude dans l’estimation. Interprétation du graphique :
- Analyse Des données
- Dispersion des données :
- Pour les faibles valeurs de DIS (proche de 0-2), on remarque une forte dispersion des valeurs de CRIM, allant de 0 à plus de 75.
- Cela pourrait indiquer que certaines zones proches des centres d’emploi ont des caractéristiques spécifiques qui augmentent considérablement la criminalité (par exemple, densité de population, type d’activité économique).
- Valeurs extrêmes :
- Il existe des points très éloignés de la tendance générale (outliers), comme ceux où CRIM dépasse 50 pour des DIS faibles. Ces valeurs pourraient représenter des quartiers très particuliers.
- Fiabilité de la relation :
- La bande grise est relativement étroite sur une grande partie de la plage des données, ce qui suggère que la relation linéaire est raisonnablement fiable.
- Cependant, pour les valeurs élevées de DIS (supérieures à 10), la bande s’élargit, indiquant moins de données disponibles pour estimer la relation dans cette région. Mon hypothèse sur le manque de données pourrait être liée à une diminution des plaintes dans les zones ayant un accès difficile aux zones policières (raison sociale, géographique ou peut-être peut-on également envisager l’impact des regards biaisés de la police lors des dépôts de plaintes…). Il est intéressant de constater que le taux de criminalité baisse légèrement avec la baisse de quantité de données ramassée.
Ce graphique montre qu’il existe une tendance globale selon laquelle la criminalité diminue à mesure que la distance aux centres d’emploi augmente. Cependant, cette relation n’est pas parfaite, car il existe une grande dispersion pour les faibles valeurs de DIS, et des valeurs extrêmes peuvent influencer l’interprétation.
- Dispersion des données :
Relation entre CRIM et LSTAT :
ggplot(boston, aes(x = LSTAT, y = CRIM)) +
geom_point(alpha = 0.4) +
geom_smooth(method = "lm", color = "red")
Un pourcentage élevé de population à faible statut socio-économique pourrait être corrélé avec un taux de criminalité plus élevé.
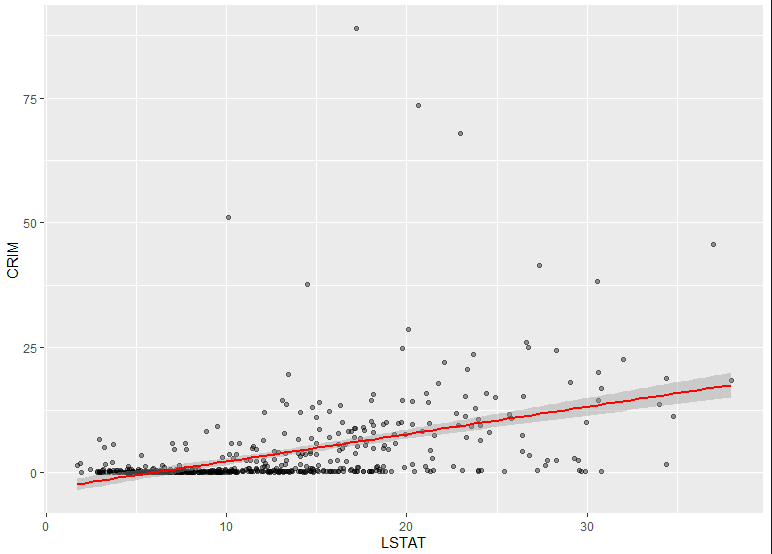
- Analyse des données
- Relation positive entre LSTAT et CRIM :
- La ligne rouge montre que lorsque le pourcentage de population à faible statut socio-économique (LSTAT) augmente, le taux de criminalité (CRIM) tend à augmenter également.
- Cette relation positive est conforme à l’hypothèse selon laquelle les zones avec des populations plus défavorisées peuvent avoir des taux de criminalité plus élevés.
- Dispersion et outliers :
- Une forte dispersion des points est visible, particulièrement pour des valeurs élevées de LSTAT. Cela suggère que la relation n’est pas parfaitement linéaire.
- On remarque plusieurs outliers (valeurs extrêmes), notamment des points où CRIM dépasse 50, ce qui pourrait indiquer des quartiers très spécifiques ou des anomalies dans les données. 2. Précision de l’estimation :
- La bande grise est relativement étroite pour des valeurs faibles à modérées de LSTAT (0-20), ce qui indique une estimation plus fiable dans cette plage.
- Cependant, pour des valeurs élevées de LSTAT (au-delà de 25), la bande s’élargit, reflétant une incertitude accrue en raison du manque de données ou de la variabilité dans ces zones.
- Relation principale : Plus le pourcentage de population défavorisée (LSTAT) est élevé, plus le taux de criminalité (CRIM) tend à augmenter, mais la relation est influencée par une variabilité importante.
- Relation positive entre LSTAT et CRIM :
Je vais essayer d’affiner l’observation à l’aide d’une dummy pour les groupes socio-économiques :
Cr&ation d’une dummy pour identifier les zones avec un pourcentage de population défavorisée (LSTAT) supérieur à un seuil critique, par exemple 20 %.
boston$High_LSTAT <- ifelse(bostong$LSTAT > 20, 1, 0)
lin_reg_high_lstat <- lm(CRIM ~ High_LSTAT, data = boston)
summary(lin_reg_high_lstat)
Interprétation : Si le coefficient associé à cette dummy est significatif, cela indiquerait que les zones avec une forte proportion de population défavorisée ont un taux de criminalité significativement différent.
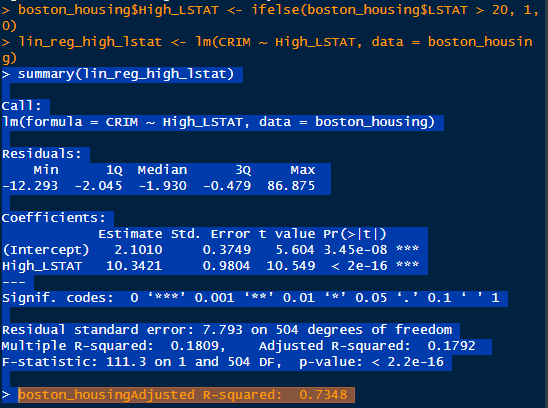
###
Résumé du modèle
- Intercept (Estimate = 2.1010) :
- Lorsque High_LSTAT = 0 (c’est-à-dire lorsque LSTAT ≤ 20), le taux de criminalité moyen est 2.10.
- High_LSTAT (Estimate = 10.3421) :
- Lorsque High_LSTAT = 1 (c’est-à-dire lorsque LSTAT > 20), le taux de criminalité augmente en moyenne de 10.34, par rapport à la base (High_LSTAT = 0).
-
**Pr(> t ) pour High_LSTAT** : - La valeur est extrêmement faible (2.4e-16), ce qui indique que l’effet de High_LSTAT est hautement significatif. Cela signifie qu’il existe une différence significative dans le taux de criminalité entre les zones où LSTAT est faible (≤ 20) et élevé (> 20).
- R² (Multiple R-squared = 0.1809) :
- Le modèle explique environ 18% de la variance dans le taux de criminalité (CRIM). Cela n’est pas élévé et n’explique qu’une petite partie du taux de crimilaité.
- Standard Error (7.793) :
- La dispersion des résidus est relativement élevée, ce qui suggère que d’autres variables pourraient également jouer un rôle important pour expliquer CRIM.
- LSTAT est un bon prédicteur :
- Lorsque LSTAT (pourcentage de population défavorisée) dépasse 20, le taux de criminalité est significativement plus élevé. Cela valide l’hypothèse que les zones à forte proportion de population défavorisée sont associées à des taux de criminalité plus élevés.
Je décide donc d’ajouter une nouvelle colone à mon dataset et d’enlever l’ancienne colone Lstat:
boston <- boston %>%
mutate(High_LSTAT = ifelse(LSTAT > 20, 1, 0)) %>%
select(-LSTAT)
Relation entre CRIM et AGE :
ggplot(boston, aes(x = AGE, y = CRIM)) +
geom_point(alpha = 0.4) +
geom_smooth(method = "lm", color = "red")
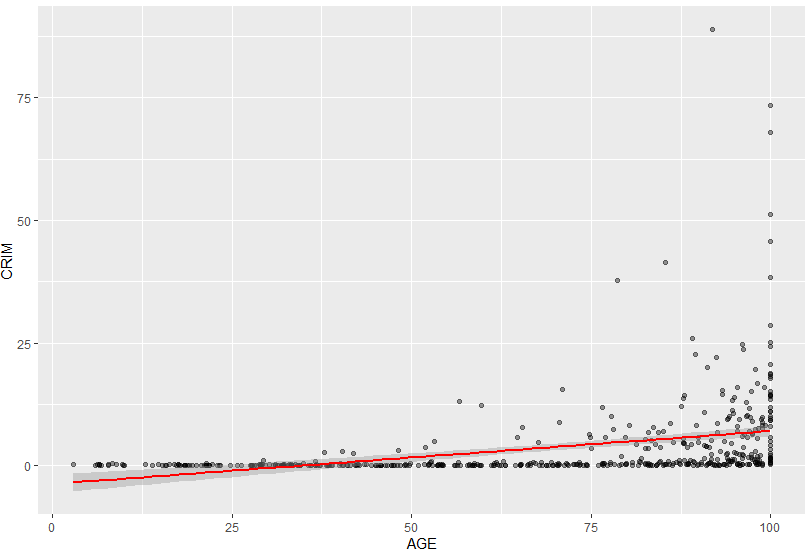
- Analyse des données
- Ligne rouge (ligne de régression) :
- La ligne rouge montre une légère relation positive entre AGE (proportion de logements anciens) et CRIM (taux de criminalité). Cela signifie que, globalement, à mesure que la proportion de logements anciens augmente, le taux de criminalité tend à augmenter légèrement.
- Bande grise (intervalle de confiance) :
- La bande grise est étroite pour une grande partie de l’intervalle, indiquant une certaine précision dans l’estimation de la relation linéaire.
Cependant, l’incertitude augmente légèrement pour des valeurs très élevées de AGE (vers 100), ce qui est probablement dû à une plus grande dispersion des données dans cette plage.
- Dispersion des données :
- Les données montrent que, pour des valeurs de AGE proches de 100 (zones où presque tous les logements sont anciens), il existe une grande variabilité dans les taux de criminalité. Certaines zones ont un taux très élevé (CRIM > 50), tandis que d’autres ont des valeurs proches de 0.
Pour des valeurs plus faibles de AGE (0-50), la dispersion est beaucoup plus faible, et les taux de criminalité sont majoritairement bas.
- Relation globale :
- La relation entre AGE et CRIM est faible mais positive. Cela signifie que l’ancienneté des logements pourrait avoir une influence sur le taux de criminalité, mais d’autres facteurs pourraient également jouer un rôle important.
- Valeurs extrêmes (outliers) :
- Les valeurs élevées de CRIM pour des AGE proches de 100 pourraient représenter des quartiers spécifiques où d’autres facteurs (par exemple, densité de population, revenus, ou proximité de centres industriels) augmentent la criminalité.
- Ligne rouge (ligne de régression) :
Hypothèses possibles :
- Quartiers anciens et criminalité :
- Les quartiers avec une forte proportion de logements anciens pourraient être associés à des conditions socio-économiques spécifiques (par exemple, manque de rénovation, faible attractivité économique), contribuant à un taux de criminalité plus élevé.
- Autres facteurs en jeu :
- La relation entre AGE et CRIM est loin d’être forte. Cela suggère que d’autres variables (comme LSTAT ou DIS) pourraient expliquer davantage la variation de CRIM.
Je décide de faire CUT ainsi que DUMMY:
La variable AGE est une variable continue (proportion de logements anciens). Cependant, il peut être difficile d’interpréter ou de modéliser cette variable telle qu’elle est. En utilisant un cut, je peu diviser AGE en groupes, ce qui permettra de mieux comprendre les relations (discrétes) non linéaires.
Un dummy (variable binaire) peut être utile pour capturer un effet spécifique, comme par exemple :
- Différencier les zones où une majorité des logement anciens (AGE > 50) ou récents (AGE <= 50).
- Tester si les quartiers avec des logements très anciens (AGE > 75) ont un effet significatif sur la criminalité.
boston <- boston %>%
mutate(AGE_category = cut(AGE,
breaks = c(0, 25, 50, 75, 100),
labels = c("0-25%", "26-50%", "51-75%", "76-100%"),
include.lowest = TRUE))
ggplot(boston_housing, aes(x = AGE_category, y = CRIM)) +
geom_boxplot(fill = "skyblue") +
labs(title = "Relation entre les catégories d'AGE et CRIM",
x = "Catégories de logements anciens (AGE)",
y = "Taux de criminalité (CRIM)")
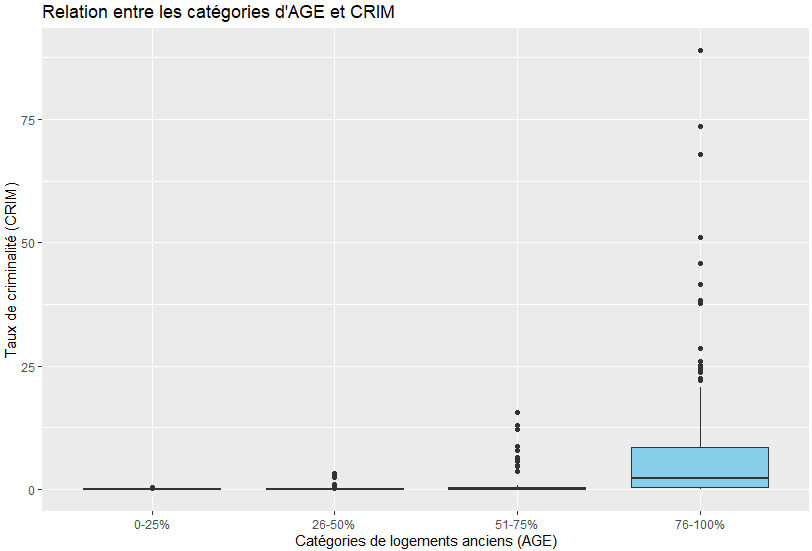
On observe que plus les proportions de maison jeune par rapport au qaurtier sont fort (entre 0 et 25% max d’apartement ancien) le taux de criminalité est faible. PLus l’age général augmente, plus la disparitée est grande. On peut globalement en déduire que les quartier avec plus de 75 de vielles maisons sont les quartier avec le plus fort taux de criminalité. Toutefois, on observe également une grande disparité: certains quartiers sont proche de zero, contrairement à d’autre. Cela signifie que cette variable à bien un impacte,
- La tendance suggère que les quartiers avec une proportion très élevée de logements anciens (76-100%) sont associés à des taux de criminalité plus élevés que les quartiers avec des logements récents (0-75%).
- Cela pourrait refléter des conditions socio-économiques spécifiques aux quartiers anciens, comme un manque d’investissements, une densité de population plus élevée, ou d’autres facteurs contribuant à une augmentation de la criminalité.
On remarque que la valeur médiane reste proches des autres tranches d’age. On peut en déduire que globalement, la violence se concentre sur quelques quartier ciblé, dans la tranche d’age de plus de 75 ans.
boston <- boston %>%
mutate(AGE_old_dummy = ifelse(AGE > 75, 1, 0))
ggplot(boston, aes(x = factor(AGE_old_dummy), y = CRIM)) +
geom_boxplot(fill = "orange") +
scale_x_discrete(labels = c("AGE <= 75%", "AGE > 75%")) +
labs(title = "Relation entre AGE_old_dummy et CRIM",
x = "Ancienneté des logements (AGE_old_dummy)",
y = "Taux de criminalité (CRIM)")
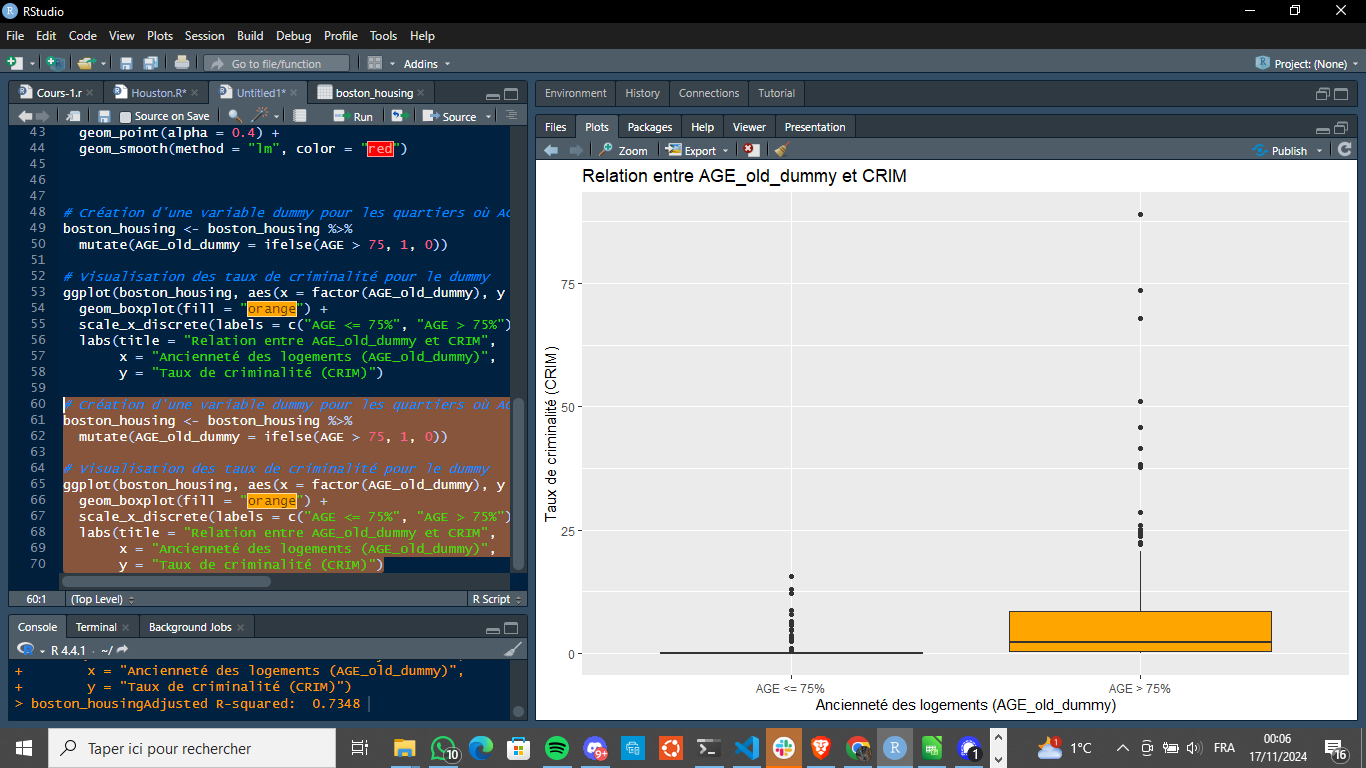
Ce boxplot compare le taux de criminalité (CRIM) entre deux groupes de quartiers :
- AGE ≤ 75% : Quartiers où moins de 75% des logements sont anciens.
- AGE > 75% : Quartiers où plus de 75% des logements sont anciens.
Il y a une grande disparité dans la colonne AGE > 75%.
nous allons faire analyser un peu plus cette collone et la divisée en trois parties et faire trois nouvelles colonne dummy:
Relation entre CRIM et TAX
ggplot(boston, aes(x = TAX, y = CRIM)) +
geom_point(alpha = 0.6) +
geom_smooth(method = "lm", color = "orange") +
labs(title = "Relation entre TAX et Criminalité (CRIM)",
x = "Taux d'imposition foncière (TAX)", y = "Taux de criminalité (CRIM)")
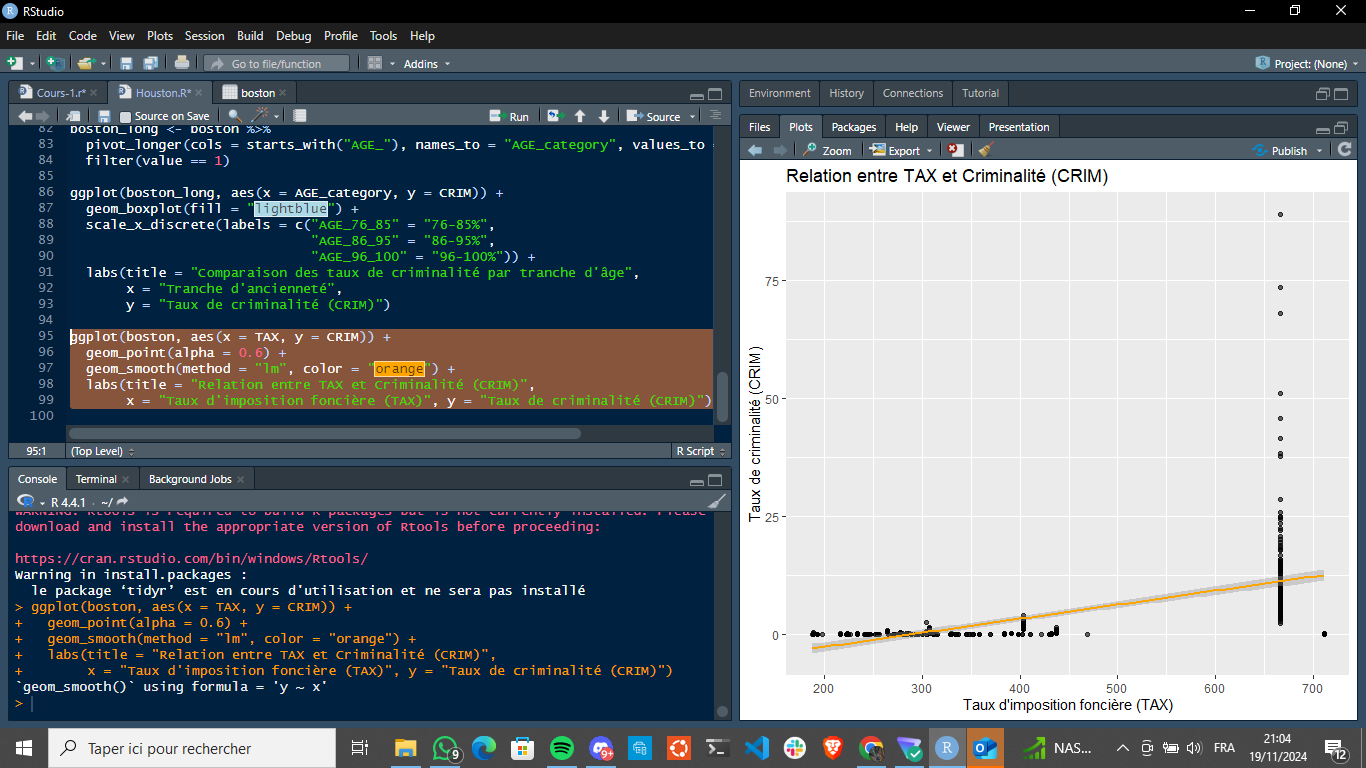
La relation est plutôt évidente: Nous avons deux zone bien distincte, une bande grise (taux des 95%) très resserrée et la relation est croissante: Plus les TAXES sont élevée, plus le taux de criminalitées augmente. On peut associer ce phénomène au fait que les quartier les plus taxés sont ceux où s’ynstallent les personnes ayant une capacité financiére, et donc matérielle plus importante.
Relation entre CRIM et NOX
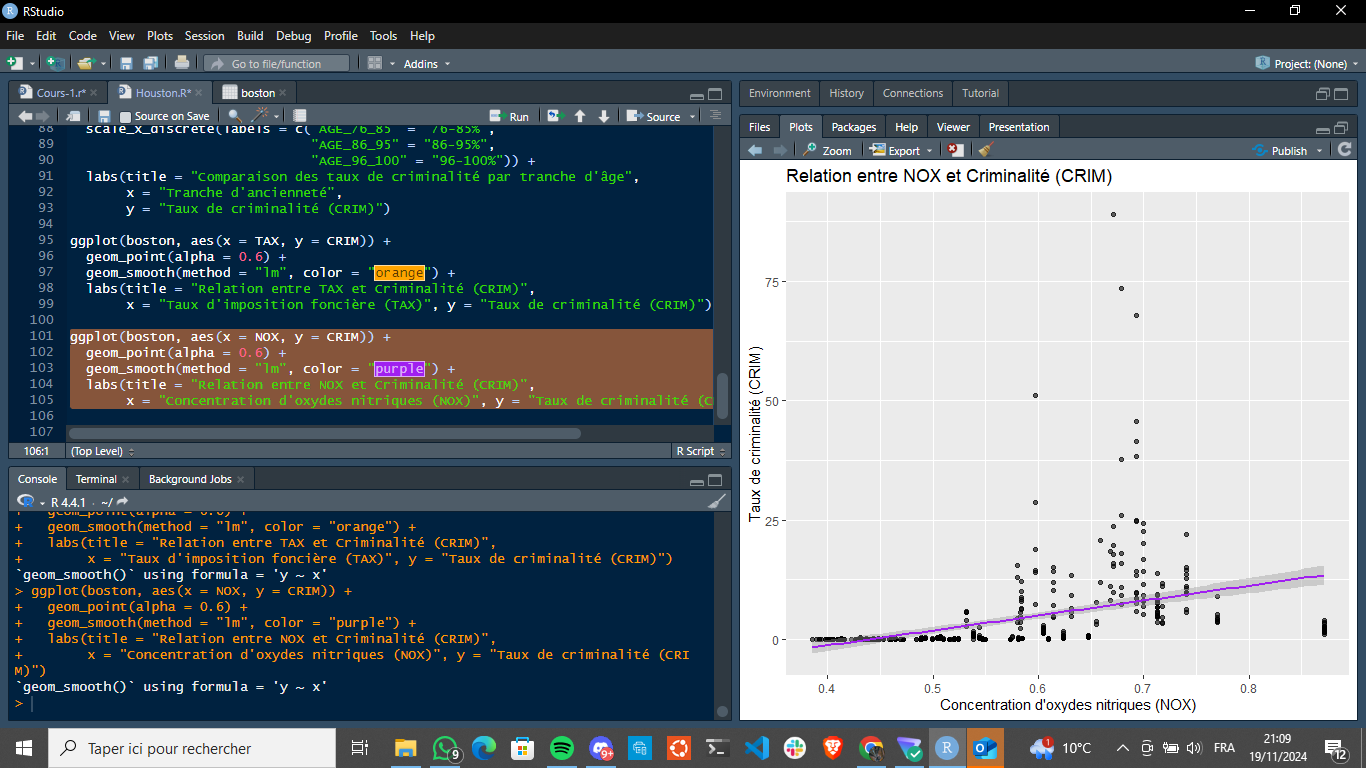
Création du modèle de régression linéaire:
Régréssion avant modification et explroation du dataset:
Ici, nous faisons une première régréssion linéaire en utilisant toutes les datas afin d’avoir un aperçu général.
#regression avant traitement du data set
lin_reg1 <- lm(CRIM ~ ., data = boston)
summary(lin_reg1)
lin_reg2 <- step(lin_reg1, direction = "backward", )
summary(lin_reg2)
résultat:
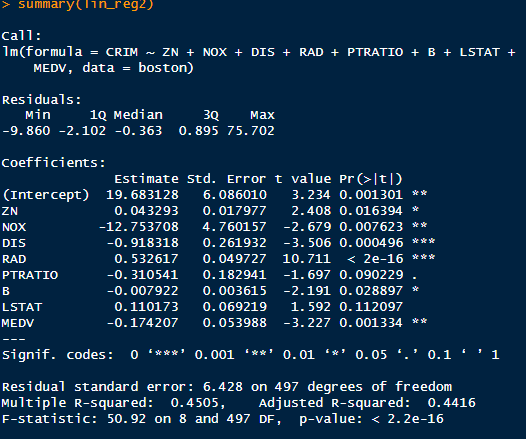
Intercept (Intercept)
- Valeur estimée : 17.032288
- Cela représente la valeur de CRIM (taux de criminalité) lorsque toutes les variables explicatives sont à zéro.
- Interprétation :
- Dans le contexte de ce modèle, un intercept élevé pourrait indiquer un certain niveau de criminalité même sans contribution des variables explicatives. Je suppose que d’autres éléments sont lié à la criminalité qu’on n’à pas ici. Il pourrait être intéressant de chercher à connaitre le nombre d’habitants par logement,
Residual Standard Error
Pour évaluer si le RSE est “bon” ou “mauvais”, il faut le mettre en contexte avec l’échelle de la variable cible (CRIM).
Si on regarde le boxplot et l’ histogramme, la majorité des valeurs de CRIM semblent être proches de 0 avec une longue traîne allant jusqu’à 88.
Si j’ai bien compris, résidual standar error étant compris dans la partie proche de la médianne, alors cela signifie que les erreurs moyennes de 6.428 unités peuvent être significatives, surtout si beaucoup de valeurs se situent dans une plage basse (ex. : 0-10).
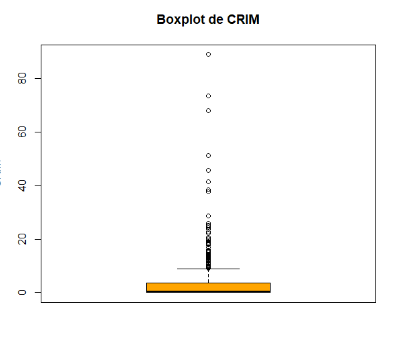
Il se peut erreur moyenne de 6.428 pourrait indiquer que le modèle a du mal à bien prédire les valeurs basses.
F-statistic est de 50.92 et sa p-value associée est < 2.2e-16.
- Une p-value aussi faible montre que ton modèle global est hautement significatif.
- Cela signifie qu’au moins une des variables explicatives a un effet significatif sur CRIM.
- Forces et limites :
- Bien que le modèle soit significatif, cela ne garantit pas que toutes les variables explicatives individuelles soient utiles .
- Contexte du R² :
-
modèle explique 45% de la variance (R2=0.4505), ce qui est raisonnable.
R2=0.4505R^2 = 0.4505
-
Cependant, il reste 55% de variance inexpliquée, ce qui pourrait être dû à des facteurs non inclus dans le modèle ou à une non-linéarité dans les relations.
-
Estimate
On observe un estimate de -12,75 pour la variable NOX. Cela signifie que cette variable a un impact significatif et important sur la cibleCRIM. Pour une augmentation de 1 unité de NOX, et toutes les autres variables restant constantes, la variable cible CRIM est estimée diminuer de 12,75 unités.
Analyse des variables
Voici un résumé rapide basé sur les données et le résumé du modèle vu dans les captures :
Variables significatives (p-value < 0.05) : À garder
- ZN : p-value significative et coefficient positif. Impact sur CRIM.
- NOX : p-value très faible, coefficient élevé et négatif. Impact significatif.
- DIS : p-value significative, coefficient négatif. Impact notable.
- RAD : p-value significative, coefficient positif. Impact important.
- PTRATIO : p-value significative, coefficient négatif.
Variables non significatives (p-value > 0.05)
- B : p-value élevée, coefficient très faible. Peu d’impact sur CRIM.
- LSTAT : p-value légèrement au-dessus de 0.05.
- MEDV : p-value élevée, impact non significatif.
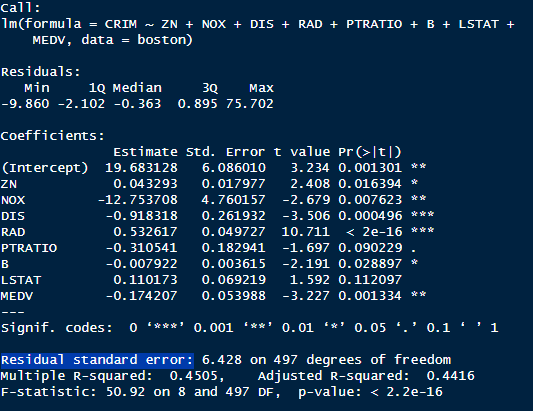
Voici le résultat après enlevé ces variables:
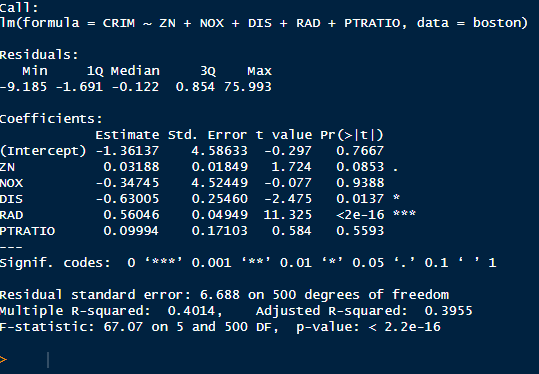
Globalement le modéle est moins performant (adjusted R-Squared est plus bas)
Faisons une autre régrassion en utilisant seulement les valeur aillant une valeur significative
r
lin_reg_simplified <- lm(CRIM ~ DIS + RAD, data = boston)
summary(lin_reg_simplified)
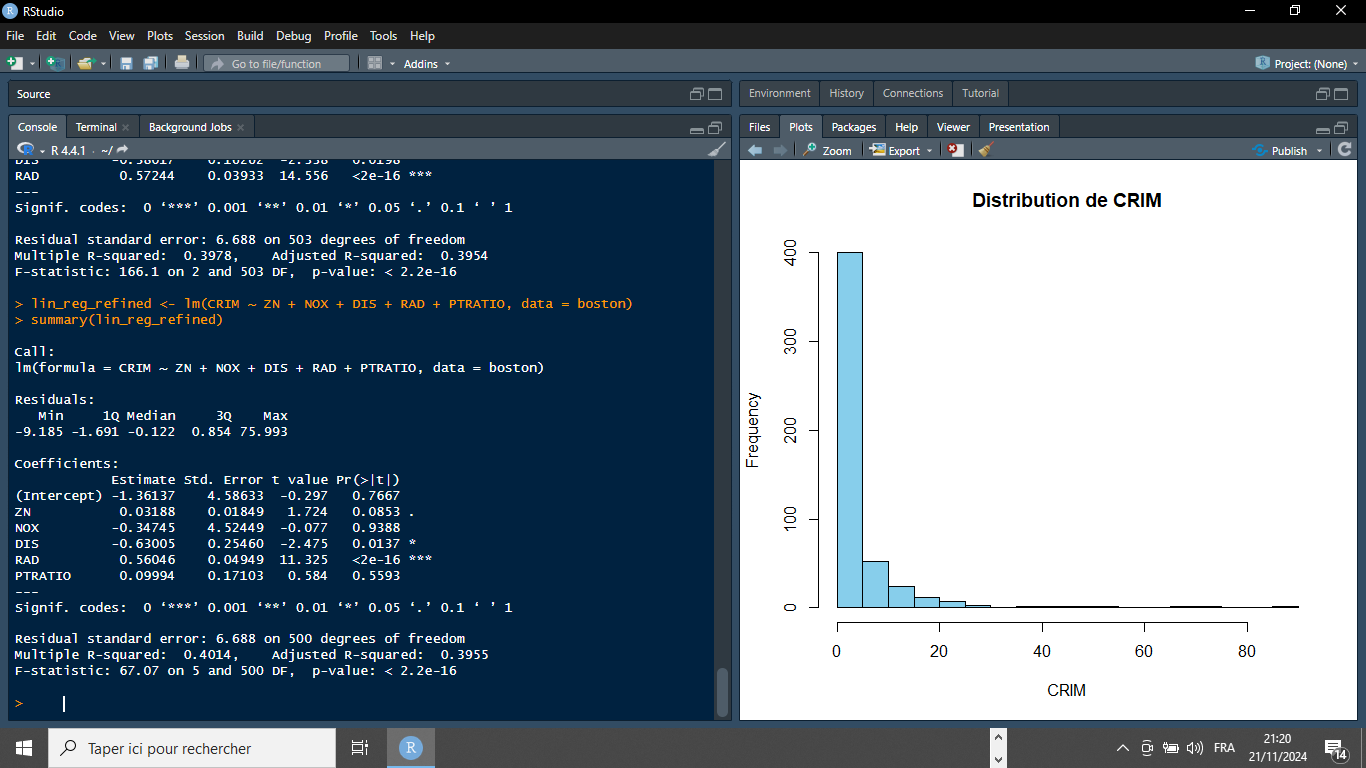
Le modèle simplifié avec les variables DIS et RAD reste globalement significatif (F-statistic = 166.1, p-value < 2.2e-16) et explique 39,5 % de la variance de CRIM (Adjusted R² = 0.3954). Les deux variables sont statistiquement significatives :
- DIS présente un effet négatif sur CRIM (-0.63, p-value = 0.0137).
- RAD présente un effet positif (0.56, p-value < 2e-16).
Le Residual Standard Error (RSE) est de 6.688, similaire au modèle précédent, mais avec moins de variables. Ce modèle est donc plus simple à interpréter, bien qu’il soit légèrement moins performant.
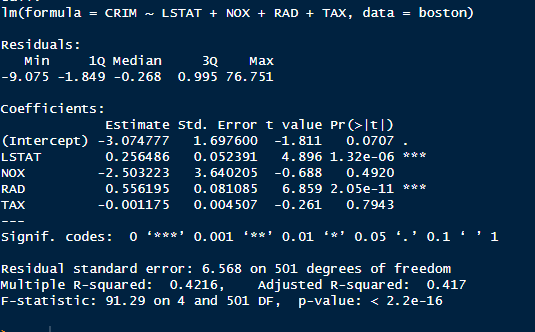
Le modèle avec les variables LSTAT, NOX, RAD, et TAX explique 41,7 % de la variance de CRIM (Adjusted R² = 0.417) avec une erreur moyenne (RSE) de 6.568. Le modèle est globalement significatif (F-statistic = 91.29, p-value < 2.2e-16).
Parmi ces variables :
- Seules LSTAT (p-value < 0.001) et RAD (p-value < 0.001) ont un impact significatif sur CRIM.
- Les variables NOX et TAX ne sont pas significatives et pourraient être retirées pour simplifier le modèle.
Une version simplifiée avec uniquement LSTAT et RAD conserverait probablement des performances similaires tout en étant plus interprétable.
CONCLUSION:
Nous disposons d’un modèle de régression linéaire relativement efficace, mais manquant de précision.
Il semble qu’en général, des variables supplémentaires seraient nécessaires pour affiner le modèle, notamment dans les zones à faible criminalité où les données semblent potentiellement insuffisantes.
De plus, il est probable que d’autres facteurs influencent le taux de criminalité, mais qu’ils ne sont pas encore pris en compte dans notre modèle actuel.
Pour améliorer le modèle, nous pourrions :
- Vérifier si les zones à faible criminalité collectent correctement toutes les données pertinentes.
- Envisager la création de nouvelles variables, telles que :
- Le nombre de personnes par logement.
- L’âge moyen des résidents.
- D’autres facteurs socio-économiques potentiellement pertinents.
Ces ajustements pourraient permettre une meilleure modélisation et une interprétation plus précise des résultats.